Building RAG Systems at Enterprise Scale: Key Lessons and Challenges
Enterprise reality: Building retrieval-augmented generation (RAG) systems for large, messy corporate document collections is far more challenging than tutorials suggest.
Building RAG Systems at Enterprise Scale: Key Lessons and Challenges
Enterprise reality: Building retrieval-augmented generation (RAG) systems for large, messy corporate document collections is far more challenging than tutorials suggest. After implementing RAG across multiple enterprises (banks, pharma, legal) with 20K–50K+ documents, several hard-earned lessons emerged about data quality, chunking strategy, metadata, hybrid search, and evaluation.
Garbage In, Garbage Out: Document Quality Matters
Enterprise documents are often garbage in terms of data quality. Decades-old scanned PDFs, OCR artifacts, and inconsistent formats wreak havoc on retrieval. Research confirms that OCR errors or "noise" in low-quality scans significantly degrade retrieval accuracy (OCR Hinders RAG, Lost in OCR Translation?). Successful RAG pipelines first assess document quality and route files accordingly, pristine text uses full parsing, while noisy scans get simplified processing. This document quality detection step (using OCR confidence or formatting consistency) prevents bad data from polluting your knowledge base.

Figure 1: Garbage documents lead to garbage results
Don't Chunk Blindly, Preserve Structure
Naively chopping every document into fixed-size chunks (512 tokens) often yields incoherent fragments and missed context. Documents have structure: sections, tables, conclusions. Effective RAG respects these boundaries with hierarchical chunking. For example, split scientific papers by Abstract/Methods/Results, and financial reports by sections and tables. Studies show that moving beyond uniform paragraph chunking to leverage structural elements improves retrieval and QA accuracy (Enhancing Retrieval Augmented Generation, Vision-Guided Chunking). By preserving logical sections, the system can retrieve the right granularity, broad answers from a whole paragraph, or a specific detail from a single sentence, without losing context.

Figure 2: Hierarchical chunking, preferably using vision-language models, preserves complex document structures
Metadata and Domain Context Over Embedding Magic
In real deployments, metadata is king. Pure semantic vector search often misses crucial context. Adding domain-specific metadata filters transforms "content-blind" search into context-aware retrieval (Hybrid Retrieval-Augmented Generation: A Practical Guide, Leveraging Enterprise Metadata in RAG). Define schemas relevant to your domain (patient age group, document type, region, quarter, regulatory category) and tag documents accordingly. A user query mentioning "pediatric FDA trials" can then trigger filters for pediatric and FDA, drastically narrowing results. This outperforms any embedding tweak. In fact, the best systems combine semantic embeddings with metadata and keyword filters, hybrid retrieval, rather than relying on one approach. This mitigates failures like acronym ambiguity or missing cross-references by catching exact matches and relationships that vectors alone overlook.
Don't Ignore Tables, They're Critical
Enterprise knowledge lives in tables: think financial spreadsheets, clinical trial results, product specs. Yet standard RAG pipelines tend to flatten or omit tables, losing relationships between rows and columns. This is a huge blind spot. Recent research on hybrid document QA notes that typical embeddings struggle with structured tables, missing accurate data retrieval. Treat tables as first-class citizens in your pipeline. Use specialized table parsing to preserve structure (CSV conversion or hierarchical JSON). Store both a semantic summary and the raw table values as context. By indexing tables properly, your RAG system can answer precise questions like "What was the exact dosage in Table 3?" correctly, instead of hallucinating or skipping these details.
Figure 3: Tables are critical for enterprise knowledge
Models and Infrastructure: Scale Pragmatically
Choosing the right language model and deployment setup is about balancing quality, cost, and data privacy. While GPT-5 class APIs are powerful, they're often impractical at enterprise scale due to high usage costs and sensitive data. We found open-source models fine-tuned on domain data (Alibaba's Qwen-32B) delivered comparable domain accuracy at a fraction of the cost, with the benefit of on-premise deployment (7 months of Qwen in production, Qwen Wikipedia). Industry reports echo this: open models give enterprises flexibility to fine-tune terminology and enjoy lower cost and improved data control (Red Hat on quantized models). Infrastructure-wise, a quantized 30B model on an in-house GPU can handle most queries with acceptable latency. The key is robust engineering: manage GPU memory, queue requests, and monitor throughput. Enterprises value reliability and compliance more than squeezing out an extra 2% accuracy from a fancy model.
Evaluate and Iterate, Benchmark Everything
Finally, building a quality RAG agent doesn't end at deployment, rigorous evaluation is critical. As RAG adoption grows, so does the need to test these systems thoroughly on their target tasks. Set up benchmarks with realistic queries (including multi-hop questions that require linking information across documents). Track metrics for retrieval accuracy, answer correctness, and especially hallucination rates. In our experience, regular evaluations catch regressions and blind spots early, whether acronyms being misinterpreted or certain document types consistently underperforming. New tools are emerging to help with this. For example, Vecta provides actionable evaluations for AI agents, running multi-hop benchmarks across different semantic granularities to halve your hallucinations and ensure you can ship with confidence. By continually measuring and refining, you turn RAG from a promising prototype into a trusted enterprise workhorse.
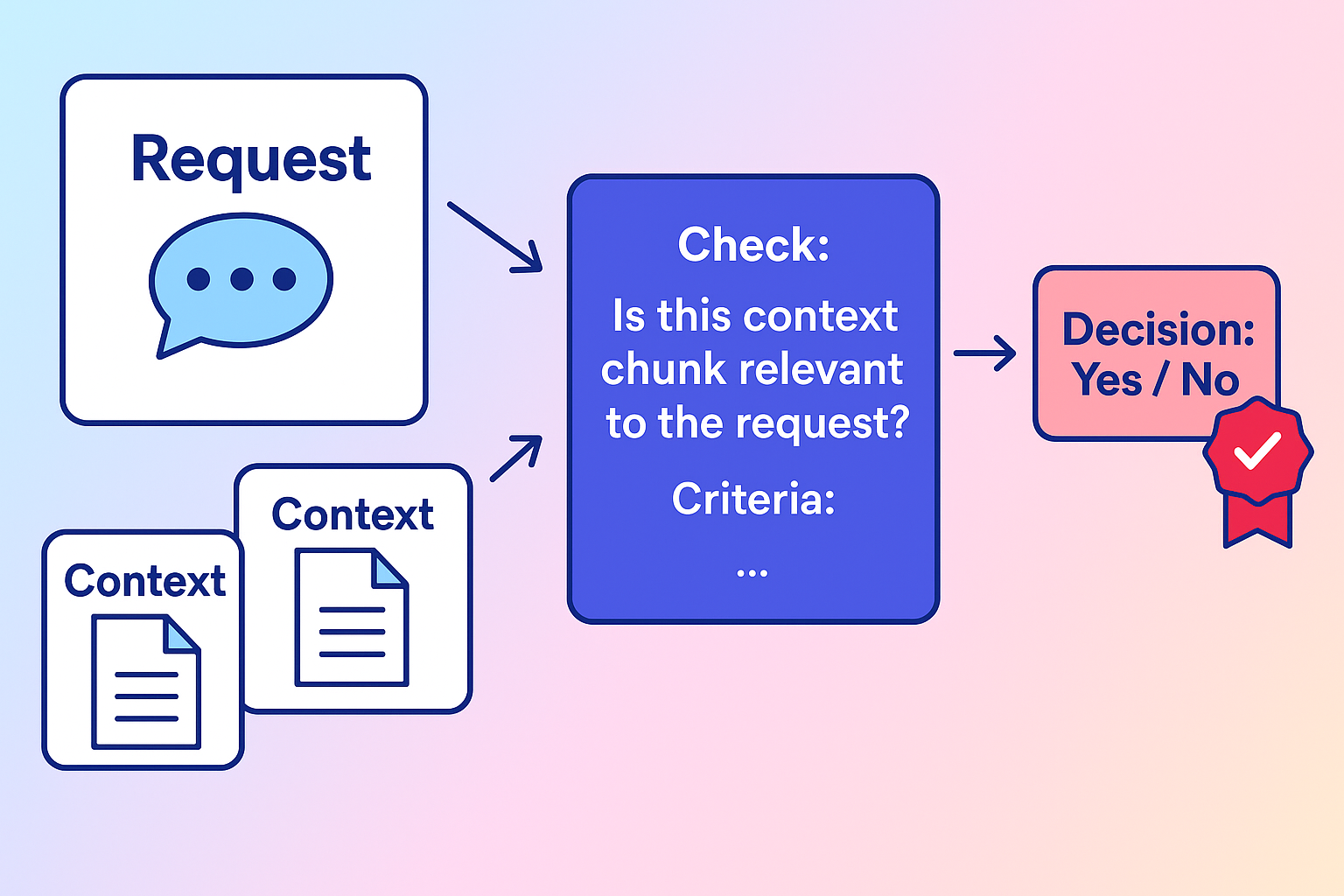
Figure 4: Vecta stress-tests every benchmark entry with a wide retrieval sweep and LLM-as-a-judge validation.
Under the hood, every synthetic benchmark entry passes through a two-step relevance gauntlet. First, we run a wide, high-recall semantic search across your knowledge base to surface any chunk that might help answer the question. Then a panel of parallel LLM-as-a-judge calls reviews those candidates, promoting every chunk they agree is relevant into the official citation list. That way your recall and precision numbers stay anchored on comprehensive ground truth instead of partial context.

Figure 5: Benchmarking is critical to reduce hallucinations, catch regressions, and fix your RAG pipeline before it causes churn
Conclusion
Building enterprise-scale RAG systems is as much an engineering challenge as an NLP challenge. Clean your inputs, preserve structure, leverage metadata, mix retrieval techniques, handle tables, and choose pragmatic models, then test relentlessly. The reward is a system that can unlock decades of buried institutional knowledge, delivering accurate answers in seconds instead of hours.