Getting Started with RAG Evaluation
Learn the fundamentals of evaluating RAG systems, from basic metrics to advanced benchmarking techniques.
Getting Started with RAG Evaluation
Retrieval-Augmented Generation (RAG) systems have become essential for building AI applications that can access and reason over large knowledge bases. However, evaluating these systems presents unique challenges that traditional ML evaluation approaches don't address.
Why RAG Evaluation Matters
RAG systems combine retrieval and generation components, making evaluation more complex than traditional NLP tasks. You need to assess:
- Retrieval Quality: Are you finding the right documents?
- Generation Quality: Is the output accurate and helpful?
- End-to-End Performance: How well does the system work as a whole?
Key Evaluation Metrics
Retrieval Metrics
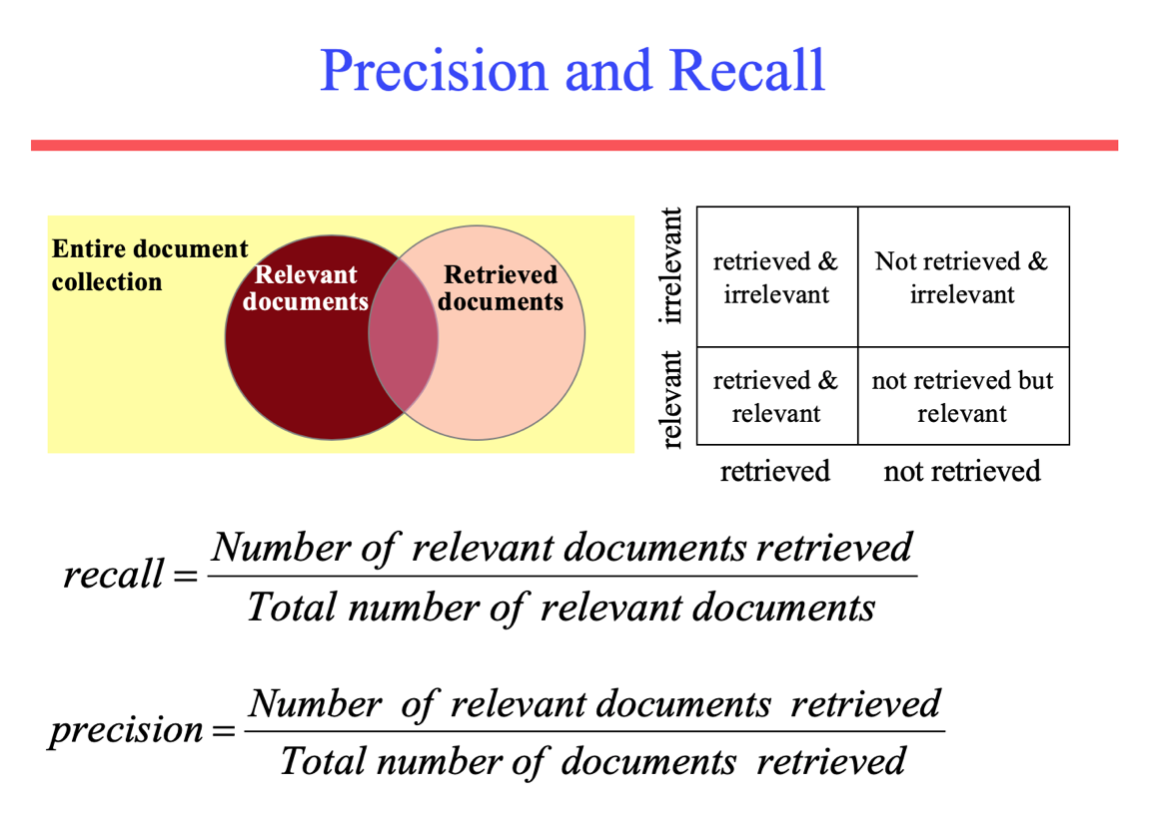
Figure 1: Precision and recall visualize how retrieval settings impact relevance coverage.
Precision@K: Measures the percentage of retrieved documents that are relevant.
def precision_at_k(retrieved_docs, relevant_docs, k):
retrieved_k = retrieved_docs[:k]
relevant_retrieved = [doc for doc in retrieved_k if doc in relevant_docs]
return len(relevant_retrieved) / k
Recall@K: Measures how many of the relevant documents were retrieved.
def recall_at_k(retrieved_docs, relevant_docs, k):
retrieved_k = retrieved_docs[:k]
relevant_retrieved = [doc for doc in retrieved_k if doc in relevant_docs]
return len(relevant_retrieved) / len(relevant_docs)
Mean Reciprocal Rank (MRR): Evaluates how quickly the first relevant document appears in the results.
This metric is used often in RAG guides and evaluations, however it is not often an important metric in practice. LLMs, especially larger SOTA models, are quite good at needle-in-a-haystack retrieval, regardless of the document's order in the list.
For completeness, here is a sample implementation anyways:
def mean_reciprocal_rank(ranked_lists):
rr_total = 0
for docs in ranked_lists:
for i, doc in enumerate(docs, start=1):
if doc.is_relevant:
rr_total += 1 / i
break
return rr_total / len(ranked_lists)
Tracking Retrieval with the Vecta SDK
Primitive metrics give you the math, but operational teams also need to plug real pipelines into their benchmark. With Vecta you can evaluate a production RAG callable and surface chunk, page, and document level precision/recall in one sweep.
from vecta import VectaAPIClient
client = VectaAPIClient(api_key="<YOUR_VECTA_API_KEY>")
def production_rag(query: str) -> tuple[list[str], str]:
"""Return (chunk_ids, generated_answer) for a query."""
pass
rag_results = client.evaluate_retrieval_and_generation(
benchmark_id="support-benchmark-v1",
retrieval_generation_function=production_rag,
evaluation_name="Production RAG Smoke Test",
)
print(f"Chunk precision: {rag_results.chunk_level.precision:.3f}")
print(f"Document recall: {rag_results.document_level.recall:.3f}")
This single call exercises the same metrics as the primitives above, but it does so against your real retriever and returns structured metrics that can be stored or visualized.
Generation Metrics
Once retrieval performance is solid, focus on the quality of generated answers. For RAG systems that means obsessing over two things: accuracy (did we answer the user correctly?) and groundedness (is every claim grounded in retrieved evidence?).
Accuracy
Accuracy tracks whether the model produced the canonical answer. Rather than rely on brittle string matching, Vecta evaluates answers with grading LLMs so paraphrases and stylistic variations are not penalized.
Groundedness
Groundedness measures whether the answer is supported by the retrieved context. Lightweight heuristics can catch obvious hallucinations, but production systems lean on attribution, citation verification, or judge models that read both the answer and context to flag unsupported statements and reward grounded responses.
Measuring Generation with the Vecta SDK
Continuing the example above, the same RAG callable can be scored for generation quality. Vecta computes accuracy and groundedness across every benchmark question and returns structured metrics you can monitor over time.
generation = rag_results.generation_metrics
print(f"Answer accuracy: {generation.accuracy:.3f}")
print(f"Answer groundedness: {generation.groundedness:.3f}")
Because the retrieval and generation metrics come from the exact same evaluation run, it becomes easy to pinpoint whether regressions stem from the search stack or the language model.
End-to-End Metrics
RAG systems should also be evaluated holistically. Typical metrics include task success rate, user satisfaction scores, or domain-specific KPIs such as ticket deflection in a support workflow.
Tips for Getting Started
- Begin with a small set of representative queries and documents.
- Use automated evaluation tools to track regressions as your system evolves.
- Visualize failures: inspecting incorrect responses alongside their retrieved passages often reveals easy wins.