Two and a Half Methods to Cut LLM Token Costs
Explore some lesser-known techniques to optimize your LLM token usage and reduce costs.
Two and a Half Methods to Cut LLM Token Costs
Only a few weeks ago, I checked in on the bill for a client's in-house LLM-based document parsing pipeline. They use it to automate a bit of drudgery with billing documentation. It turns out, "just throw everything at the model" is not always a sensible path forwards. Every prompt instruction, table row, every duplicate OCR pass, prompt expansion, etc... It adds up.
By the end of last month, the token spend graph looked like a pump-and-dump nightmare.
Please learn from our mistakes. Here, we're sharing a few interesting (well... at least we found them interesting) ways to cut LLM token spend.
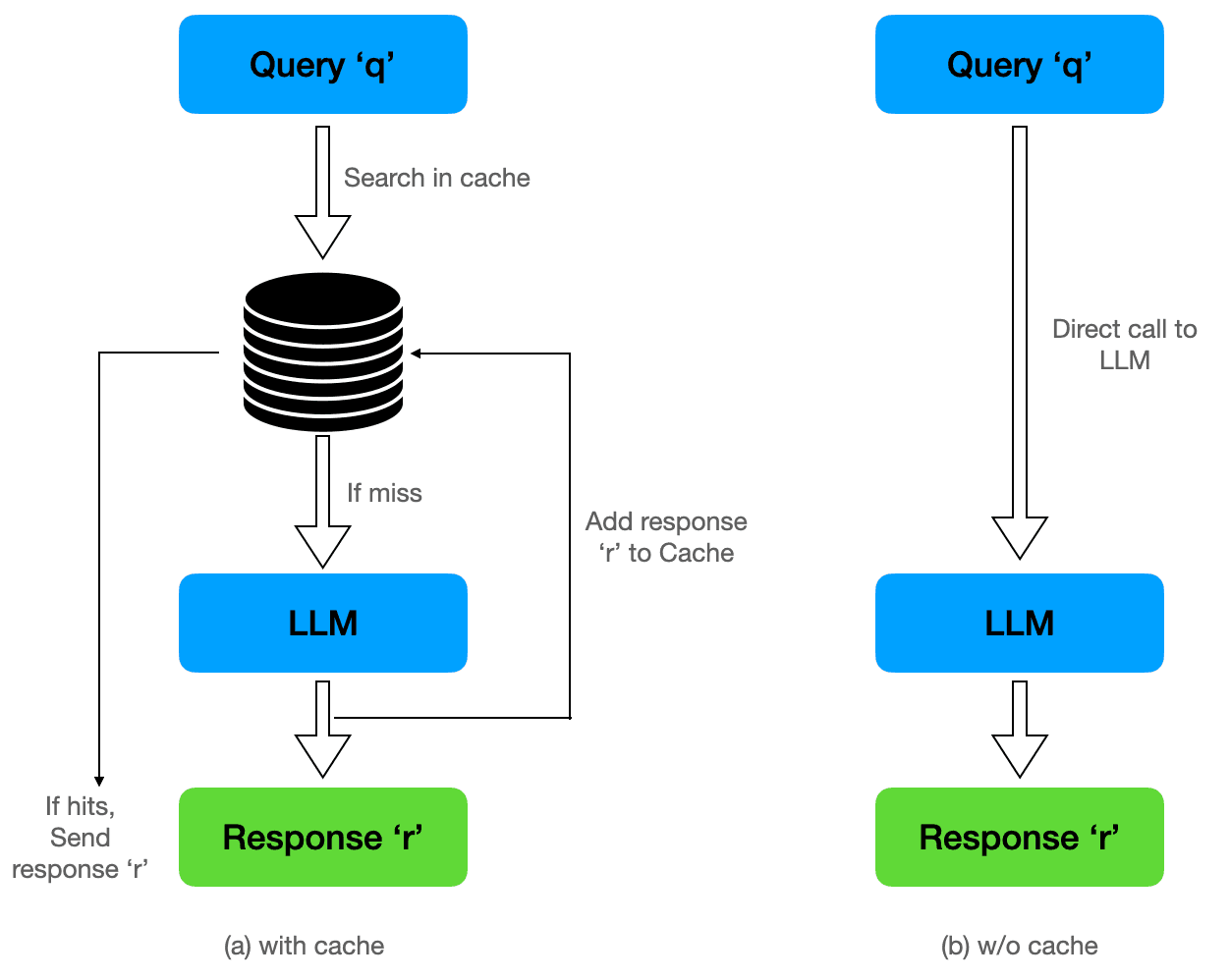
Prompt Caching for Long, Repeated Prefixes
Many calls repeat the same front-matter (system prompt, tool schemas, policies, style guide, etc.).
Figure 1: Prompt caching can save costs on repeated tokens
- Providers now cache those repeated prefix tokens so you don't pay full price to reprocess them each time.
- On Azure OpenAI, cached input tokens are billed at a discount for Standard deployments and can be free (100% discount) on Provisioned.
- Caches usually persist for minutes and require ≥1,024 identical leading tokens, with additional hits every 128 tokens.
- You often can't shrink essential instructions, but you can avoid paying full freight for them over and over.
Hoist all stable content to the very start of the messages array (system/developer/tool schemas) to maximize prefix identity and cache hits.
Keep those sections deterministic (no timestamps/UUIDs) and long enough to cross the 1,024-token threshold.
Tokenizer-Aware Model & Phrasing (Choose Encodings That Yield Fewer Tokens)
Different models tokenize the same text into different token counts.
- Newer OpenAI "o-series" models use o200k encodings, which tend to be more efficient than older cl100k.
- Fewer tokens for the same prompt = lower bill.
- The OpenAI cookbook emphasizes that pricing is by token, so counting and minimizing tokens directly reduces cost.
- If model A splits your prompt into 20% fewer tokens than model B (for comparable quality), that's an immediate 20% input-token savings - before any prompt engineering.
Measure with a local tokenizer (e.g., tiktoken) before you ship; pick the model whose tokenizer yields fewer tokens for your domain text.

Figure 1: Tiktoken is a fast BPE tokenizer for OpenAI models
Rewrite high-token phrases (numbers, dates, boilerplate) into forms that break into fewer tokens without changing meaning.
Always re-count after rewriting, since tokenization quirks vary by model.
LLMLingua-Style Prompt Compression (and its newer variants)
LLMLingua learns which tokens actually matter and deletes the rest before the call. I'm calling this a "half method" because it actually deteriorates the input context, potentially sabotaging efforts to extract exact details.
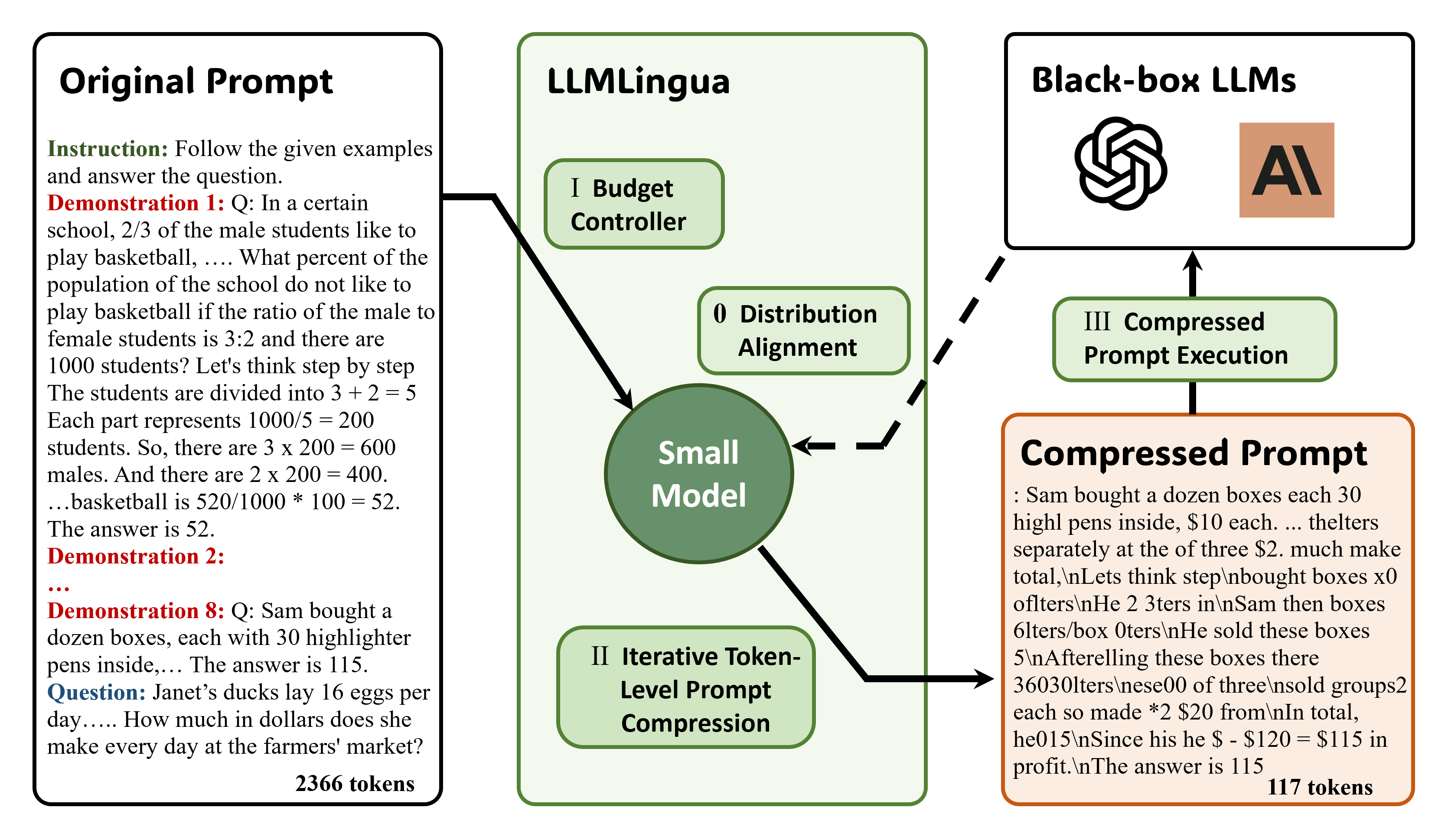
Figure 2: LLMLingua compresses prompts by learning which tokens matter
- The original paper reports up to ~20× prompt compression with little accuracy loss.
- LLMLingua-2 distills an LLM to do faster, task-agnostic, extractive compression (typically 2 - 5× compression with 1.6 - 2.9× end-to-end speedups).
- LongLLMLingua adapts the idea for long contexts and even improves RAG quality while using fewer tokens.
- Fewer input tokens → fewer billed tokens, and often shorter outputs because the model sees less fluff.
Use the open-source repo (LLMLingua) as a pre-processor in your pipeline.
Start conservative (e.g., 1.5 - 2× compression) on critical tasks; push higher on retrieval snippets and exemplars.
For RAG, compress retrieved chunks per-query (LLMLingua-2/LongLLMLingua) before assembling the final context window.