We Benchmarked 7 Chunking Strategies on Real-World Data. Most 'Best Practice' Advice Was Wrong (For Us).
We ran 7 RAG chunking strategies — fixed-size, recursive, semantic, sentence-window, and more — against real enterprise documents and measured precision, recall, and F1. The conventional wisdom was wrong for us. Here's the data.
Is the title clickbait? Yes. But read on, because our small-scale experiment revealed some surprising insights that challenge common chunking advice in the RAG community. Perhaps your pipeline looks like ours, and these findings can save you some time.
If you've built a RAG system, you've had the chunking conversation. Somebody on your team (or a Medium post) told you to "just use 512 tokens with 50-token overlap" or "semantic chunking is strictly better."
We decided to test these claims. We created a small (1M tokens) corpus of real academic papers spanning AI, mathematics, pyhsics, and computer vision. Then, we ran every document through seven different chunking strategies and measured retrieval quality and downstream answer accuracy using Vecta's evaluation pipeline.
Critically, we designed the evaluation to be fair: each strategy retrieves a different number of chunks, calibrated so that every strategy gets approximately 2,000 tokens of context in the generation prompt. This eliminates the confound where strategies with larger chunks get more context per retrieval, and ensures we're measuring chunking quality, not context window size.
The "boring" strategies won. The hyped strategies failed. And the relationship between chunk granularity and answer quality is more nuanced than most advice suggests.
The Setup
Corpus
We assembled a diverse corpus of 50 academic papers (905,746 total tokens) deliberately spanning similar disciplines, writing styles, and document structures: Papers ranged from 3 to 112 pages and included technical dense mathematical proofs pertaining to fundamental ML research. All PDFs were converted to clean markdown using MarkItDown, with OCR artifacts and single-character fragments stripped before chunking.
Chunking Strategies Tested
- Fixed-size, 512 tokens, 50-token overlap
- Fixed-size, 1024 tokens, 100-token overlap
- Recursive character splitting, LangChain-style
RecursiveCharacterTextSplitterat 512 tokens - Semantic chunking, embedding-based boundary detection (cosine similarity threshold 0.7)
- Document-structure-aware, splitting on markdown headings/sections, max 1024 tokens
- Page-per-chunk, one chunk per PDF page, using MarkItDown's form-feed (
\f) page boundaries - Proposition chunking, LLM-decomposed atomic propositions following Dense X Retrieval with the paper's exact extraction prompt
All chunks were embedded with text-embedding-3-small and stored in local ChromaDB. Answer generation used gemini-2.5-flash-lite via OpenRouter. We generated 30 ground-truth Q&A pairs using Vecta's synthetic benchmark pipeline.
Equal Context Budget: Adaptive Retrieval k
Most chunking benchmarks use a fixed top-k (e.g., k=10) for all strategies. This is fundamentally unfair: if fixed-1024 retrieves 10 chunks, the generator sees ~10,000 tokens of context; if proposition chunking retrieves 10 chunks at 17 tokens each, the generator gets ~170 tokens. The larger-chunk strategy wins by default because it gets more context, not because its chunking is better.
We fix this by computing an adaptive k for each strategy:
This targets ~2,000 tokens of retrieved context for every strategy. The computed values:
| Strategy | Avg Tokens/Chunk | Adaptive k | Expected Context |
|---|---|---|---|
| Page-per-Chunk | 961 | 2 | ~1,921 |
| Doc-Structure | 937 | 2 | ~1,873 |
| Fixed 1024 | 658 | 3 | ~1,974 |
| Fixed 512 | 401 | 5 | ~2,007 |
| Recursive 512 | 397 | 5 | ~1,984 |
| Semantic | 43 | 46 | ~1,983 |
| Proposition | 17 | 115 | ~2,008 |
Now every strategy gets ~2,000 tokens to work with. Differences in accuracy reflect genuine chunking quality, not context budget.
How We Score Retrieval: Precision, Recall, and F1
We evaluate retrieval at two granularities: page-level (did we retrieve the right pages?) and document-level (did we retrieve the right documents?). At each level, the core metrics are precision, recall, and F1.
Let be the set of retrieved items (pages or documents) and be the set of ground-truth relevant items. Then:
Precision measures: of everything we retrieved, what fraction was actually relevant? A retriever that returns 5 pages, 4 of which contain the answer, has a precision of 0.8. High precision means low noise in the context window.
Recall measures: of everything that was relevant, what fraction did we find? If 3 pages contain the answer and we retrieved 2 of them, recall is 0.67. High recall means we're not missing important information.
F1 is the harmonic mean of precision and recall. It penalizes strategies that trade one for the other and rewards balanced retrieval.
Why two granularities matter. Page-level metrics tell you whether you're pulling the right passages. Document-level metrics tell you whether you're pulling from the right sources. A strategy can score high page-level recall (finding many relevant pages) while scoring low document-level precision (those pages are scattered across too many irrelevant documents). As we'll see, the tension between these two levels is one of the main findings.
The Results
The Big Picture
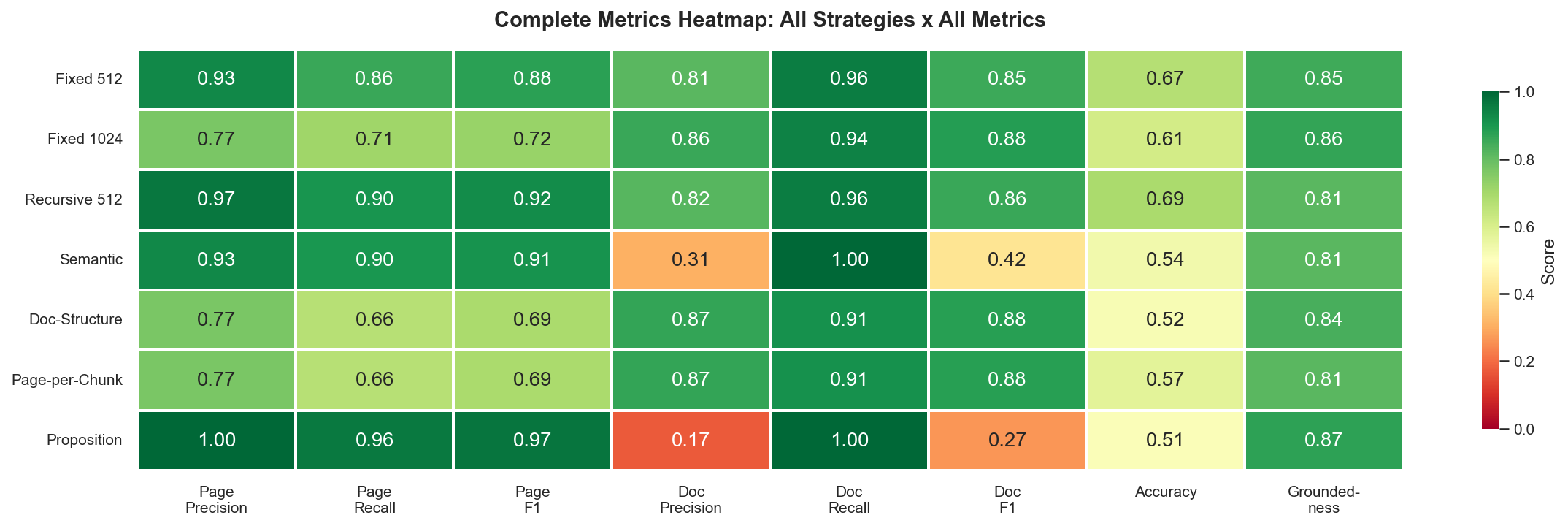
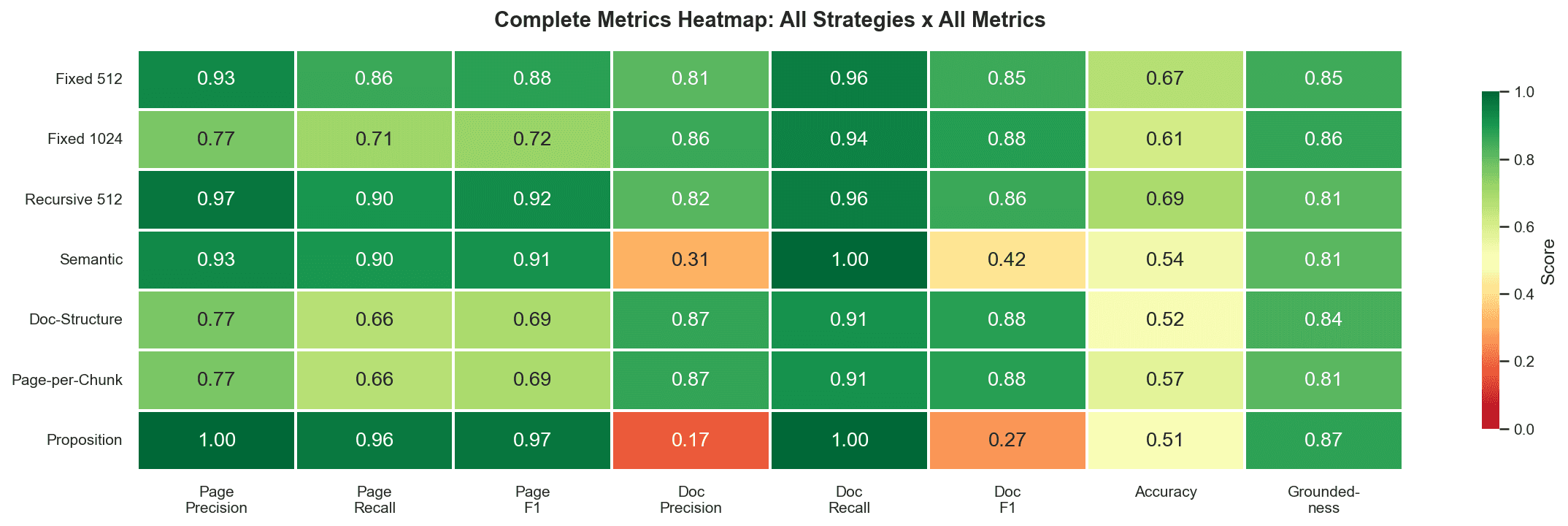
Figure 1: Complete metrics heatmap. Green is good, red is bad.
| Strategy | k | Doc F1 | Page F1 | Accuracy | Groundedness |
|---|---|---|---|---|---|
| Recursive 512 | 5 | 0.86 | 0.92 | 0.69 | 0.81 |
| Fixed 512 | 5 | 0.85 | 0.88 | 0.67 | 0.85 |
| Fixed 1024 | 3 | 0.88 | 0.72 | 0.61 | 0.86 |
| Doc-Structure | 2 | 0.88 | 0.69 | 0.52 | 0.84 |
| Page-per-Chunk | 2 | 0.88 | 0.69 | 0.57 | 0.81 |
| Semantic | 46 | 0.42 | 0.91 | 0.54 | 0.81 |
| Proposition | 115 | 0.27 | 0.97 | 0.51 | 0.87 |
Recursive splitting wins on accuracy (69%) and page-level retrieval (0.92 F1). The 512-token strategies lead on generation quality, while larger-chunk strategies lead on document-level retrieval but fall behind on accuracy.
Finding 1: Recursive and Fixed Splitting Often Outperforms Fancier Strategies
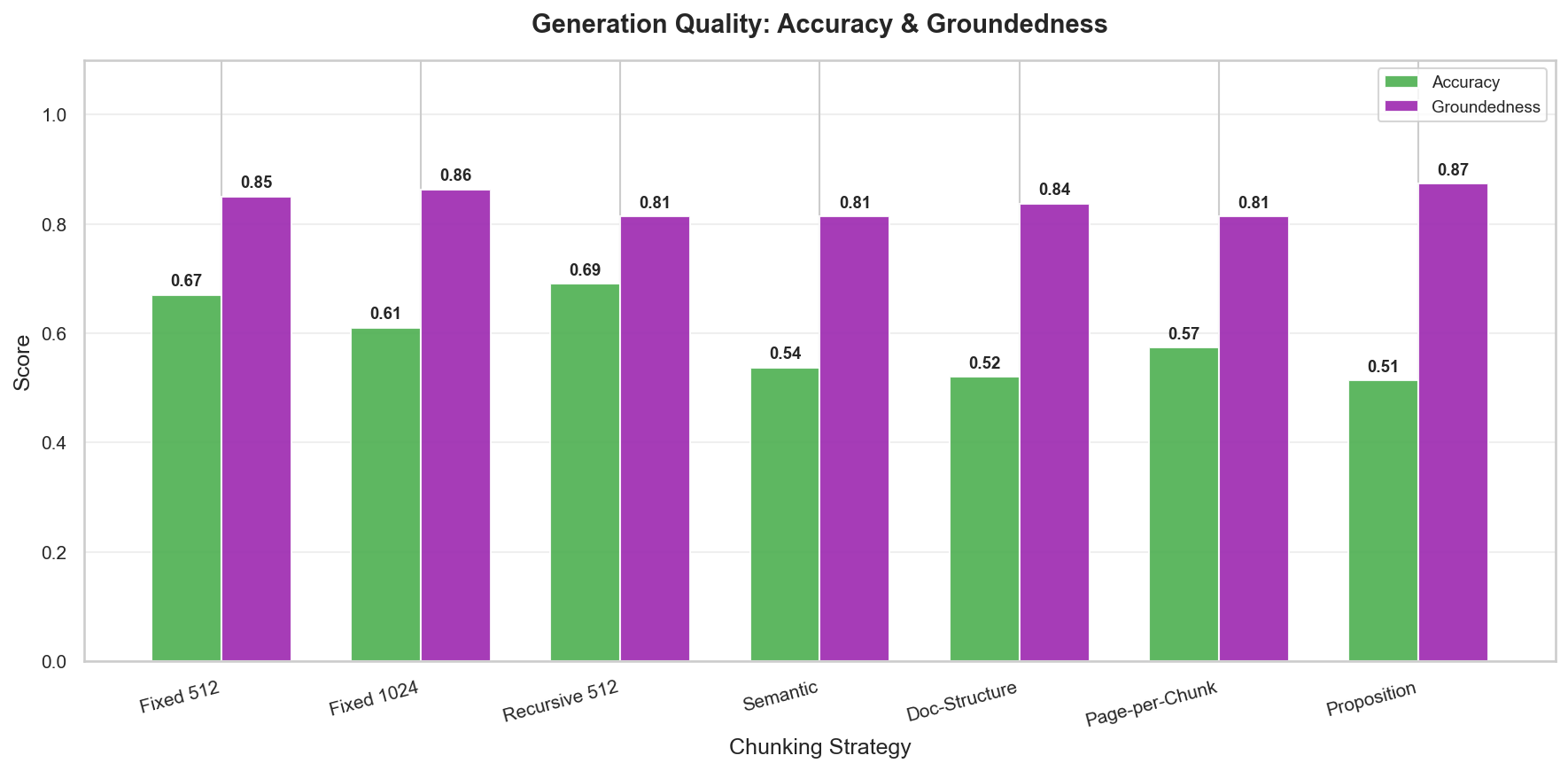
Figure 2: Accuracy and groundedness by strategy. Recursive and fixed 512 lead on accuracy.
LangChain's RecursiveCharacterTextSplitter at 512 tokens achieved the highest accuracy (69%) across all seven strategies. Fixed 512 was close behind at 67%. Both strategies use 5 retrieved chunks for ~2,000 tokens of context.
Why does recursive splitting edge out plain fixed-size? It tries to break at natural boundaries, paragraph breaks, then sentence breaks, then word breaks. On academic text, this preserves logical units: a complete paragraph about a method, a full equation derivation, a complete results discussion. The generator gets chunks that make semantic sense, not arbitrary windows that may cut mid-sentence.
Recursive 512 also achieved the best page-level F1 (0.92), meaning it reliably finds the right pages and produces accurate answers from them.
Finding 2: The Granularity-Retrieval Tradeoff Is Real
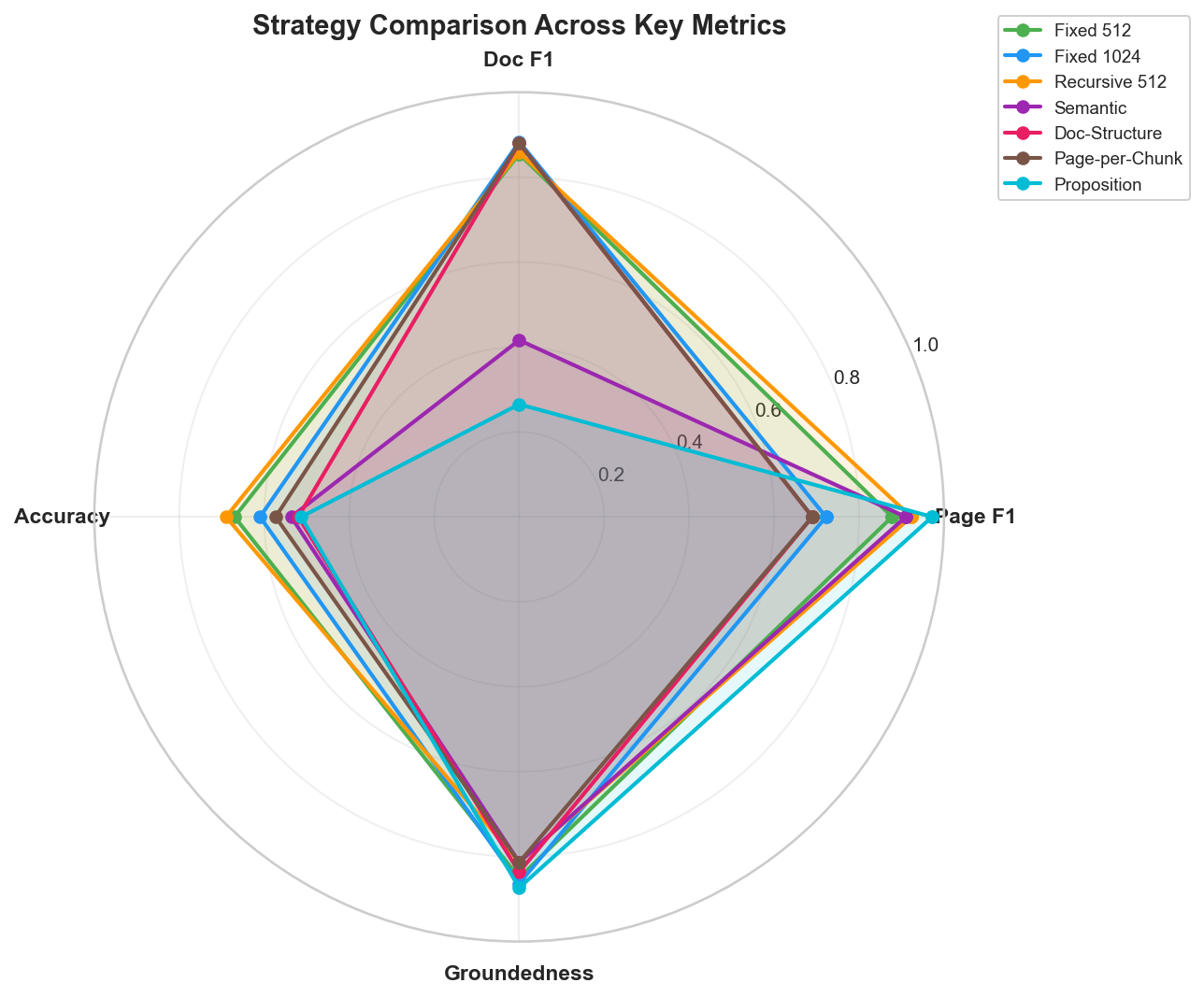
Figure 3: Radar chart, recursive 512 (orange) has the fullest coverage. Large-chunk strategies skew toward doc retrieval but lose on accuracy.
With a 2,000-token budget, a clear tradeoff emerges:
- Smaller chunks (k=5) achieve higher accuracy (67-69%) because 5 retrieval slots let you sample from 5 different locations in the corpus, each precisely targeted
- Larger chunks (k=2-3) achieve higher document F1 (0.88) because each retrieved chunk spans more of the relevant document, but the generator gets fewer, potentially less focused passages
Fixed 1024 scored the best document F1 (0.88) but only 61% accuracy. With just k=3, you get 3 large passages, great for document coverage, but if even one of those passages isn't well-targeted, you've wasted a third of your context budget.
Finding 3: Semantic Chunking Collapses at Scale
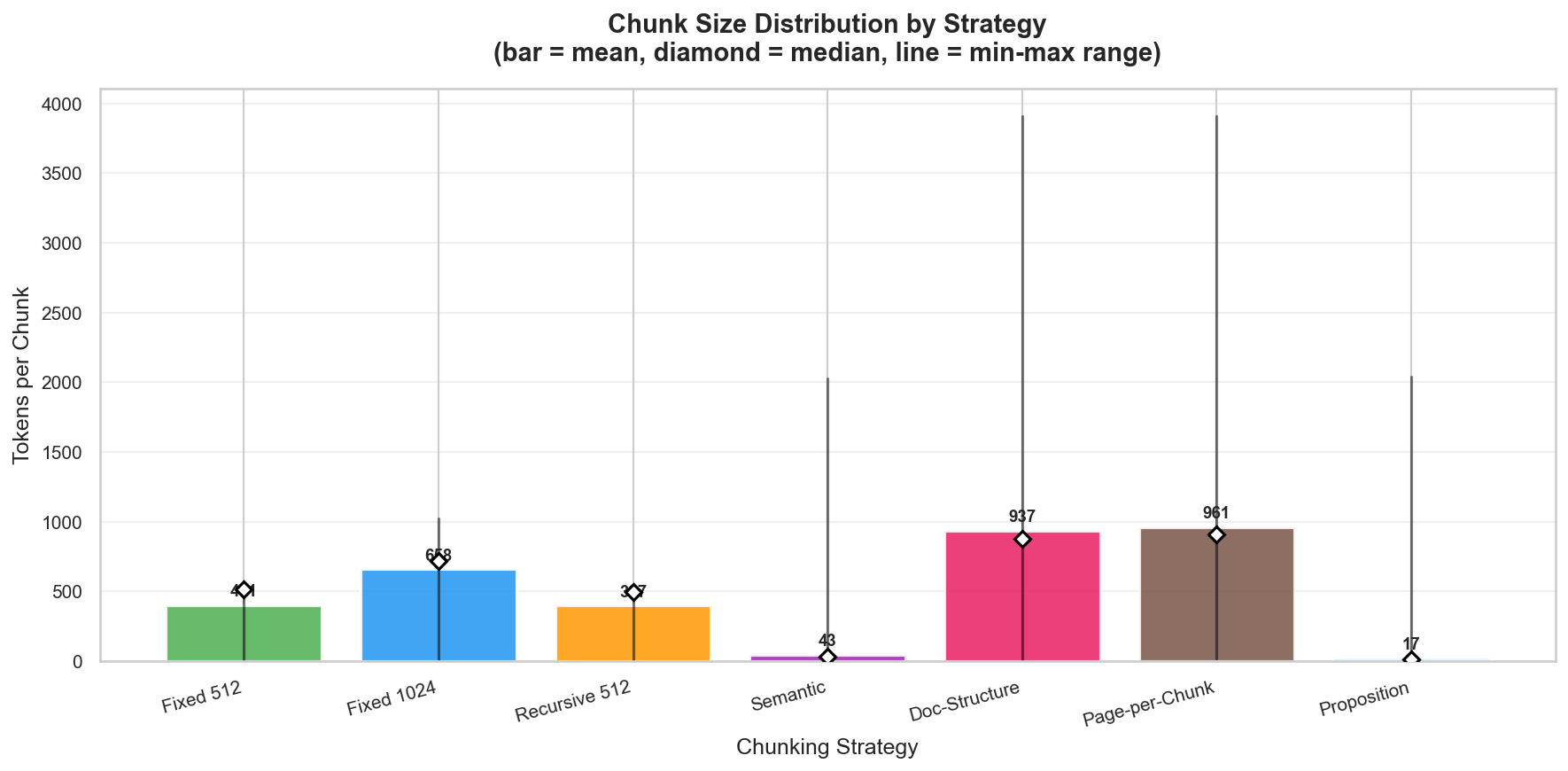
Figure 4: Chunk size distribution. Semantic and proposition chunking produce extremely small fragments.
Semantic chunking produced 17,481 chunks averaging 43 tokens across 50 papers. With k=46, the retriever samples from 46 different tiny chunks. The result: only 54% accuracy and 0.42 document F1.
High page F1 (0.91) reveals what's happening: the retriever finds the right pages by sampling many tiny chunks from across the corpus. But document-level retrieval collapses because those 46 chunks come from dozens of different documents, diluting precision. And accuracy suffers because 46 disconnected sentences don't form a coherent narrative for the generator.
The fundamental problem: semantic chunking optimizes for retrieval-boundary purity at the expense of context coherence. Each chunk is a "clean" semantic unit, but a single sentence chunk may lack the surrounding context needed for generation.
Finding 4: The Page-Level Retrieval Story
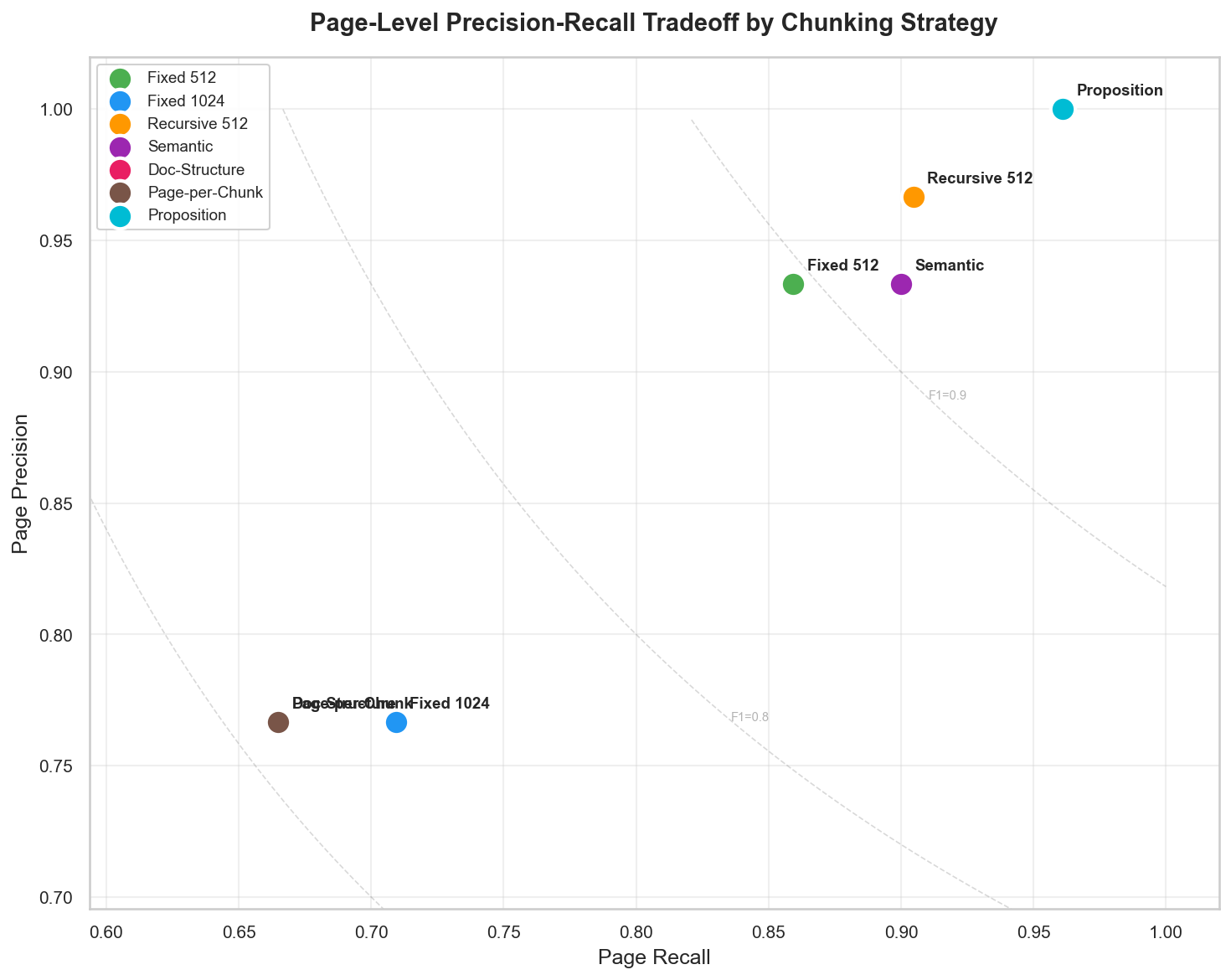
Figure 5: Page-level precision-recall tradeoff. Recursive 512 achieves the best balance.
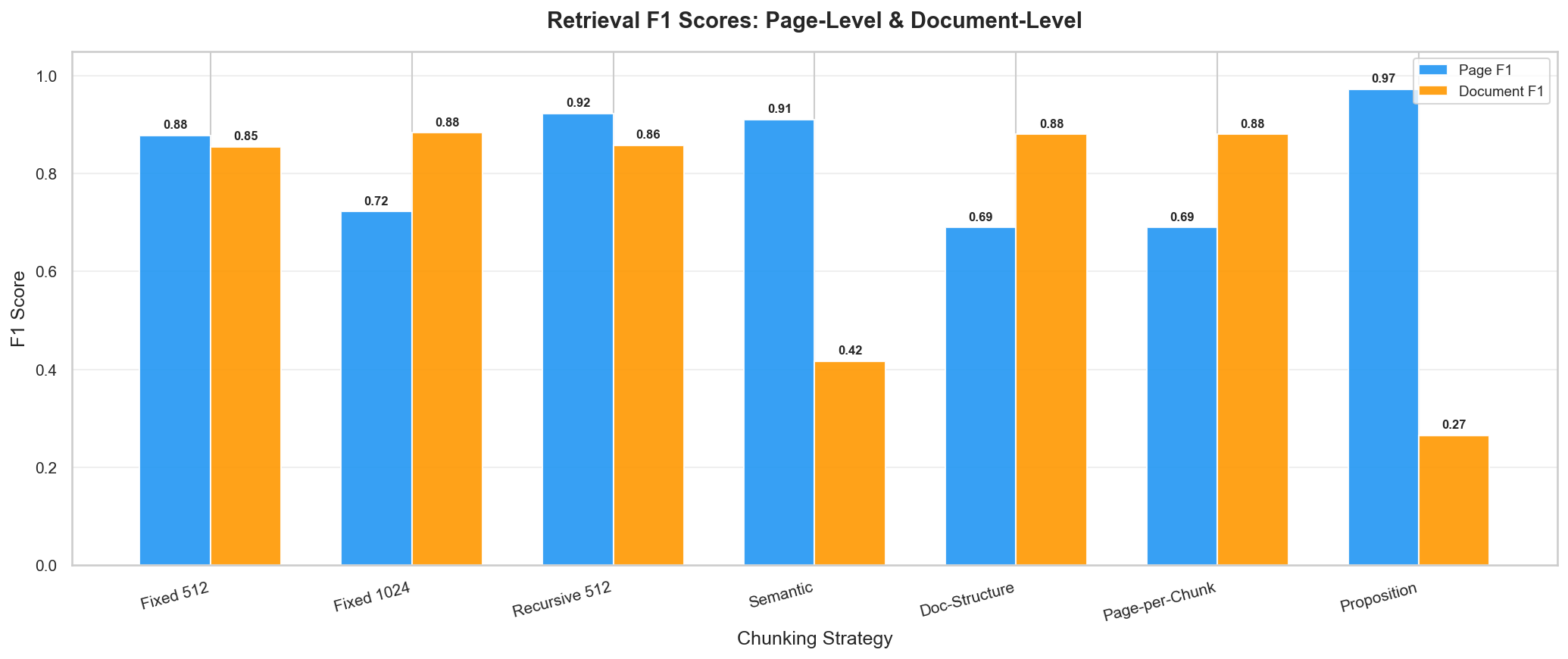
Figure 6: Page-level and document-level F1. The two metrics tell different stories.
Page-level and document-level retrieval tell opposite stories under constrained context:
- Fine-grained strategies (proposition k=115, semantic k=46) achieve high page F1 (0.91-0.97) by sampling many pages, but low doc F1 (0.27-0.42) because those pages come from too many documents
- Coarse strategies (page-chunk k=2, doc-structure k=2) achieve high doc F1 (0.88) by retrieving fewer, more relevant documents, but lower page F1 (0.69) because 2 chunks can only cover 2 pages
Recursive 512 at k=5 hits the best balance: 0.92 page F1 and 0.86 doc F1. Five chunks is enough to sample multiple relevant pages while still concentrating on a few documents.
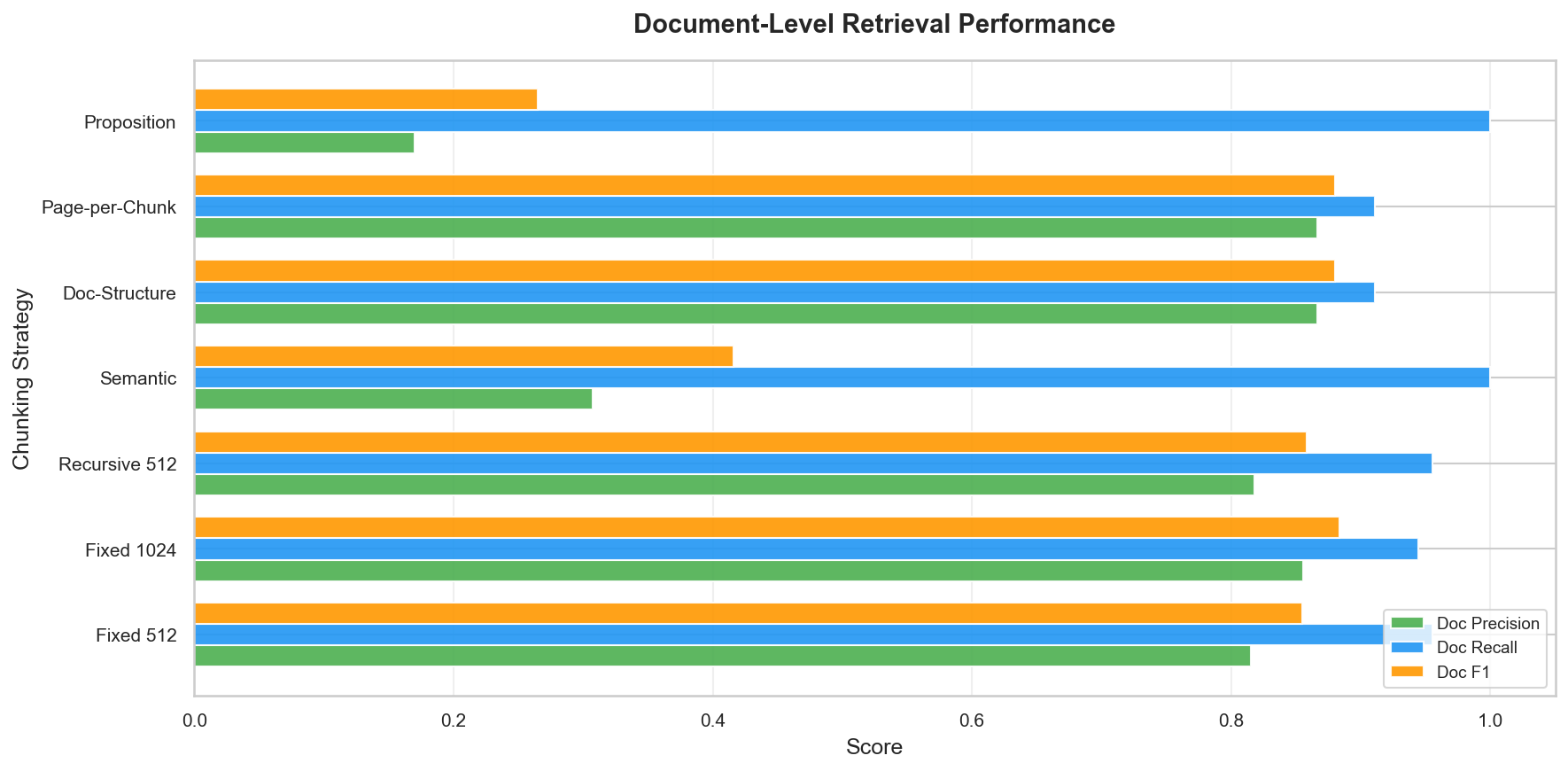
Figure 7: Document-level precision, recall, and F1 detail. Large-chunk strategies lead on precision; fine-grained strategies lead on recall.
What This Means for Your RAG System
The Short Version
- Use recursive character splitting at 512 tokens. It scored the highest accuracy (69%), best page F1 (0.92), and strong doc F1 (0.86). It's the best all-around strategy on academic text.
- Fixed-size 512 is a strong runner-up with 67% accuracy and the highest groundedness among the top performers (85%).
- If document-level retrieval matters most, use fixed-1024 or page-per-chunk (0.88 doc F1), but accept lower accuracy (57-61%).
- Don't use semantic chunking on academic text. It fragments too aggressively (43 avg tokens) and collapses on document retrieval (0.42 F1).
- Don't use proposition chunking for general RAG. 51% accuracy isn't production-ready. It's only viable if you value groundedness over correctness.
- When benchmarking, equalize the context budget. Fixed top-k comparisons are misleading. Use adaptive k = round(target_tokens / avg_chunk_tokens).
Why Academic Papers Specifically?
We deliberately chose to saturate the academic paper region of the embedding space with 50 papers spanning 10+ disciplines. When your knowledge base contains papers that all discuss "evaluation," "metrics," "models," and "performance," the retriever has to make fine-grained distinctions. That's when chunking quality matters most.
In a mixed corpus of recipes and legal contracts, even bad chunking might work because the embedding distances between domains are large. Academic papers are the hard case for chunking, and if a strategy works here, it'll work on easier data too.
How We Measured This (And How You Can Too)
We built Vecta specifically to meet the need for precise RAG evaluation software. It generates synthetic benchmark Q&A pairs across multiple semantic granularities, then measures precision, recall, F1, accuracy, and groundedness against your actual retrieval pipeline.
The benchmarks in this post were generated and evaluated using Vecta's local SDK (pip install vecta):
from vecta import VectaClient, ChromaLocalConnector, VectorDBSchema
import numpy as np
connector = ChromaLocalConnector(
client=chroma_client,
collection_name="my_chunks",
schema=VectorDBSchema(
id_accessor="id",
content_accessor="document",
metadata_accessor="metadata",
source_path_accessor="metadata.source_path",
page_nums_accessor="metadata.page_nums",
),
)
vecta = VectaClient(data_source_connector=connector)
vecta.load_knowledge_base()
benchmark = vecta.generate_benchmark(n_questions=30)
# Equal context budget: adaptive k targeting 2000 tokens
avg_tokens = np.mean([count_tokens(c.content) for c in chunks])
k = max(1, round(2000 / avg_tokens))
results = vecta.evaluate_retrieval_and_generation(
lambda q: my_rag_function(q, k=k),
evaluation_name="recursive_512",
)
Want to run similar tests? Get started here.
Limitations, Experiment Design, and Further Work
This experiment was deliberately small-scale: 50 papers, 30 synthetic Q&A pairs, one embedding model, one retriever, one generator. That's by design. We wanted something reproducible that a single engineer could rerun in an afternoon, not a months-long research project. The conclusions should be read with that scope in mind.
Synthetic benchmarks are not human benchmarks. Our ground-truth Q&A pairs were generated by Vecta's own pipeline, which means there's an inherent alignment between how questions are formed and how they're evaluated. Human-authored questions would be a stronger test. That said, Vecta's benchmark generation does produce complex multi-hop queries that require synthesizing information across multiple chunks and document locations, so these aren't trivially easy questions that favor any one strategy by default.
One pipeline, one result. Everything here runs on text-embedding-3-small, ChromaDB, and gemini-2.5-flash-lite. Swap any of those components and the rankings could shift. We fully acknowledge this. Running the same experiment across multiple embedding models, vector databases, and generators would be valuable follow-up work, and it's on our roadmap.
The equal context budget is a deliberate constraint, not a flaw. Some readers may object that semantic and proposition chunking are "meant" to be paired with rerankers, fusion, or hierarchical aggregation. But if a chunking strategy only works when combined with additional infrastructure, that's important to know. Equal context budgets ensure we're comparing chunking quality at roughly equal generation cost. A strategy that requires a reranker to be competitive is a more expensive strategy, and that should factor into the decision.
Semantic chunking was not intentionally handicapped. Our semantic chunking produced fragments averaging 43 tokens, which is smaller than most production deployments would target. This was likely due to a poorly tuned cosine similarity threshold (0.7) rather than any deliberate sabotage. But that's actually the point: semantic chunking requires careful threshold tuning, merging heuristics, and often parent-child retrieval to work well. When those aren't perfectly dialed in, it degrades badly. Recursive splitting, by contrast, produced strong results with default parameters. The brittleness of semantic chunking under imperfect tuning is itself a finding.
What we'd like to do next:
- Rerun the experiment with human-authored Q&A pairs alongside the synthetic benchmark
- Test across multiple embedding models (
text-embedding-3-large,all-MiniLM-L12-v2, open-source alternatives) and frontier LLMs (GPT-5, Opus 4.6, and Kimi K2.5) - Add reranking and hierarchical retrieval stages, then measure whether the rankings change when every strategy gets access to the same post-retrieval pipeline
- Expand the corpus beyond academic papers to contracts, documentation, support tickets, and other common RAG domains
- Test semantic chunking with properly tuned thresholds, chunk merging, and sliding windows to establish its ceiling
If you run any of these experiments yourself, we'd genuinely like to see the results.
*Have a chunking strategy that worked surprisingly well (or badly) for you? We'd love to hear about it. Reach out at hello@runvecta.com.